标题参考前端技能路线系列 (opens new window)
副标题参考 MDN (opens new window)
文章内容来源 HTTP 相关 (opens new window)
# HTTP基础
# MIME类型
媒体类型或 MIME 类型是一种标准,用来表示文档、文件或字节流的性质和格式。
浏览器通常使用MIME类型(而不是文件扩展名)来确定如何处理URL,因此Web服务器在响应头中添加正确的MIME类型非常重要
# 语法
MIME的组成结构非常简单;由类型和子类型两个字符串中间用/分隔。MIME类型对大小写不敏感,但是传统写法都是小写。
# MIME 嗅探
在缺失 MIME 类型或客户端认为文件设置了错误的 MIME 类型时,浏览器可能会通过查看资源来进行MIME嗅探。每一个浏览器在不同的情况下会执行不同的操作。因为这个操作会有一些安全问题,有的 MIME 类型表示可执行内容而有些是不可执行内容。浏览器可以通过请求头 Content-Type 来设置 X-Content-Type-Options 以阻止MIME嗅探。
# 默认类型
有两种默认类型:
- application/octet-stream
- text/plain
因为 Chrome 不能执行 application/octet-stream 格式的文件,默认操作是把它下载下来,(不同浏览器对待不能处理的文件执行的操作不一样,有些浏览器则会尝试去嗅探)。
# npm相关包
# 端口
默认http端口是80,https是443
# Headers(消息头)
# Cookie
cookie是储存与访问者的计算机中的变量.可以让我们用同一个浏览器访问同一个域名的时候共享数据。
http是无状态协议,简单的说,当你浏览了一个页面,然后转到同一个网站的另一个页面,服务器无法认识到这是同一个浏览器在访问同一个网站,每一次的访问,都是没有任何关系的。
设置cookie:
| 名称 | 说明 |
|---|---|
| maxAge | 一个数字表述从Date.now()得到的毫秒数 |
| expires | cookie过期的Date |
| path | cookie路径,默认是'/' |
| domain | cookie域名 |
| secure | 安全cookie,默认false,设置成true表示只有https可以访问 |
| httpOnly | 客户端和服务器是否可访问cookie,设置true则只有服务端可以获取,默认是true |
| overwrite | 一个布尔值,表示是否覆盖以前设置的同名的cookie(默认是false),如果是true,在同一个请求中设置相同名称的所有cookie(不管路径或域)是否在设置此cookie时从Set-Cookie标头中过滤掉。 |
注意:cookie值不能为中文,需要先用encodeURI转换为utf-8格式,取值的时候再用decodeURI转换回来。或者转为base64格式
# Content-Security-Policy
通过 csp 规则的约束,浏览器只可以加载指定可信的域名来源的内容
# Content-Disposition
Content-Disposition 响应头指示回复的内容该以何种形式展示,是以内联的形式(即网页或者页面的一部分),还是以附件的形式下载并保存到本地。可选值:
- inline 默认值是
inline,以内联形式展示 - attachment 意味着消息体应该被下载到本地
- attachment; filename="filename.jpg" 将 filename 的值预填为下载后的文件名,假如它存在的话。
# 缓存
一、浏览器缓存
Http 缓存机制分为两种,客户端缓存和服务器端缓存,而服务端缓存又分为 代理服务器缓存(例:CDN 服务)和 反向代理服务器缓存(例:Nginx 反向代理服务),强制缓存与对比缓存是可以同时存在的,并且强制缓存的优先级高于对比缓存。
- 服务端决策缓存:由服务端决定并告知客户端是否使用缓存。
- 客户端决策缓存:服务端告知客户端缓存时间后,由客户端判断并决定是否使用缓存。
对于这两种策略机制的区别,最明显的表象是:从 Chrome DevTool 中 Network 面板里看到缓存的请求,服务端决策缓存在 Status 一栏显示的是 304,而客户端决策缓存在 Status 一栏显示的是 200,不过在 Size 一栏会显示 from disk cache。
浏览器第一次请求:
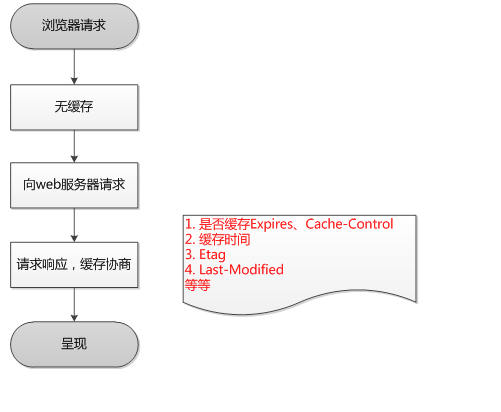
浏览器再次请求时:

二、缓存位置
从缓存位置上来说分为四种,并且各自有优先级,当依次查找缓存且都没有命中的时候,才会去请求网络。
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
三、浏览器缓存机制图 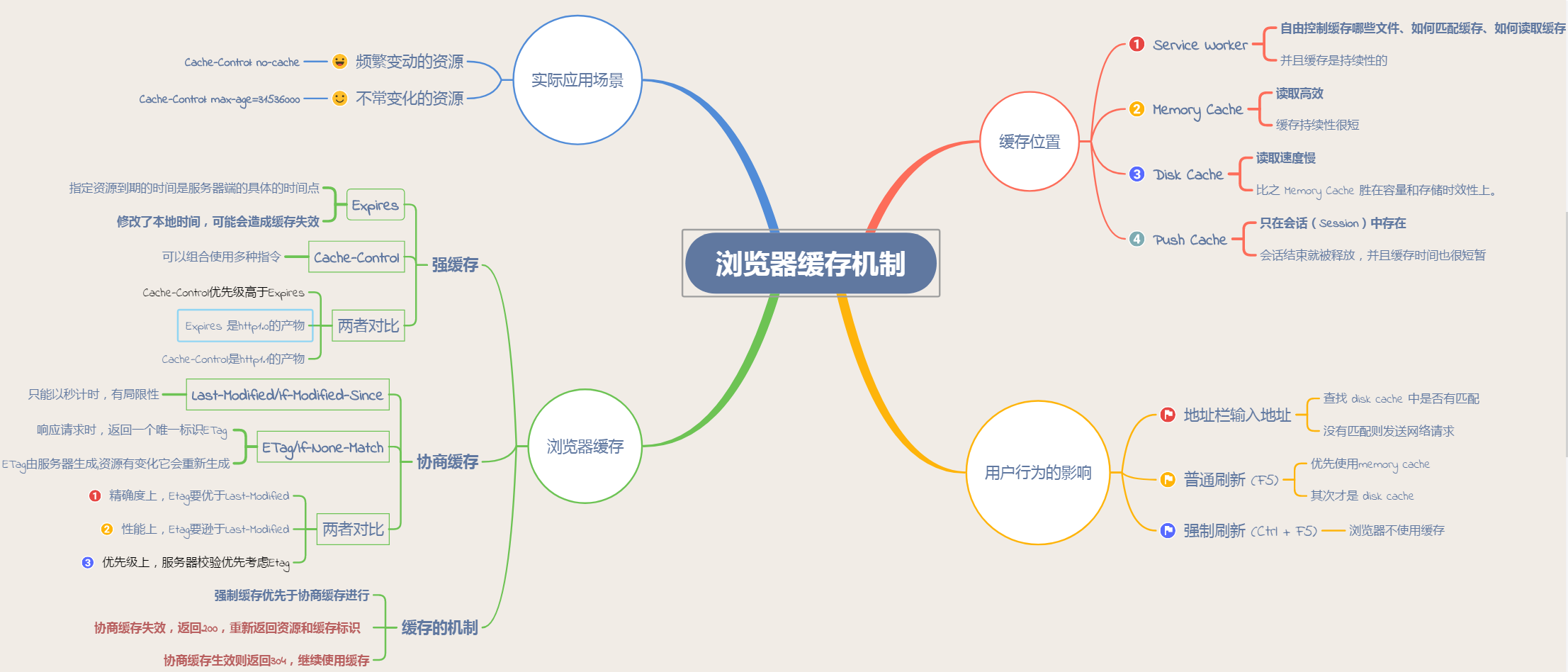
四、最佳实践
缓存的意义就在于减少请求,更多地使用本地的资源,给用户更好的体验的同时,也减轻服务器压力。所以,最佳实践,就应该是尽可能命中强缓存,同时,能在更新版本的时候让客户端的缓存失效。在更新版本之后,如何让用户第一时间使用最新的资源文件呢?在更新版本的时候,顺便把静态资源的路径改了,这样,就相当于第一次访问这些资源,就不会存在缓存的问题了。
在 webpack 中设置文件指纹:
entry:{
main: path.join(__dirname,'./main.js'),
vendor: ['react', 'antd']
},
output:{
path:path.join(__dirname,'./dist'),
publicPath: '/dist/',
filname: 'bundle.[contenthash].js'
}
综上所述,我们可以得出一个较为合理的缓存方案:
- HTML:使用协商缓存。
- CSS&JS&图片:使用强缓存,文件命名带上 hash 值。
引用:
HTTP 缓存 (opens new window)
深入 Web 缓存策略 (opens new window)
彻底弄懂 HTTP 缓存机制及原理 (opens new window)
前端缓存最佳实践 (opens new window)
# HTTP/2
http 2 相对于之前的 http 协议有以下几个优点:1.http2 采用流式传输,同时对消息头采用 hpack 压缩传输,最大限度节省网络带宽。2.使用 tcp 多路复用。3.支持传输流的优先级和流量控制机制。4.支持服务端推送
# 文章
# 问题
# 什么是网络劫持?
网络劫持一般指网站资源请求在请求过程中因为人为的攻击导致没有加载到预期的资源内容,网络请求劫持分为 dns 劫持和 http 劫持
# 下载文件的几种方式?
- 访问资源时,服务端没设置contentType,并且被解析为默认的
application/octet-stream,那么会下载该资源 - Content-Disposition设置为
attachment的资源 - HTML5 a 标签增加的 download 属性:
<a href="/images/xxx.jpg" download="panda.jpg" >My Panda</a> - 还有些场景,只能通过异步请求返回二进制内容再由前端下载。借助 download 属性,结合 Blob, Url.createObjectURL() 可以实现前端异步请求资源并导出文件